
Welcome to my first blog post with Ordr, which is hopefully the first of many. Here at Ordr we’re all about network-connected device information and providing insightful knowledge, however this comes in many forms. At its simplest form it could be data, binary, Boolean or it could even be a string, but what’s most important is its fidelity, accuracy and relevance. Globally, organizations are starting to truly embrace data, especially big-data, but they are starting to realize that they don’t want just data, what they really want is information and knowledge that they can use within their current workflows.
Connect Anything and Everything
I like to talk about living in the era of ‘connect anything and everything’; these connected devices across any wired or wireless infrastructure come in all shapes, sizes, flavors. More importantly there is a high variance historically in IT’s ability to correctly identify them and understand their risk and compliance status. In my first few months at Ordr, I had the opportunity to sit down with many customers to understand their needs. In short, our customers look to Ordr to provide valuable insights as to what is connected to their network, what exactly is that device, how it is behaving individually or compared to its peers and be able to identify those devices/endpoints that are misbehaving or perhaps possess vulnerabilities again, this is critical information and knowledge, not just data.
Ordr Data Lake for Device Enrichment
We pride ourselves on our foundational ability to identify all network-connected devices with a high degree of fidelity using deep packet inspection (DPI) to provide the insights that matter. Using the raw packet data from your network, we are able to classify all devices at-scale, then enrich that data in our Data Lake with various third-party data sources to turn it into the context that you need to help secure your infrastructure.
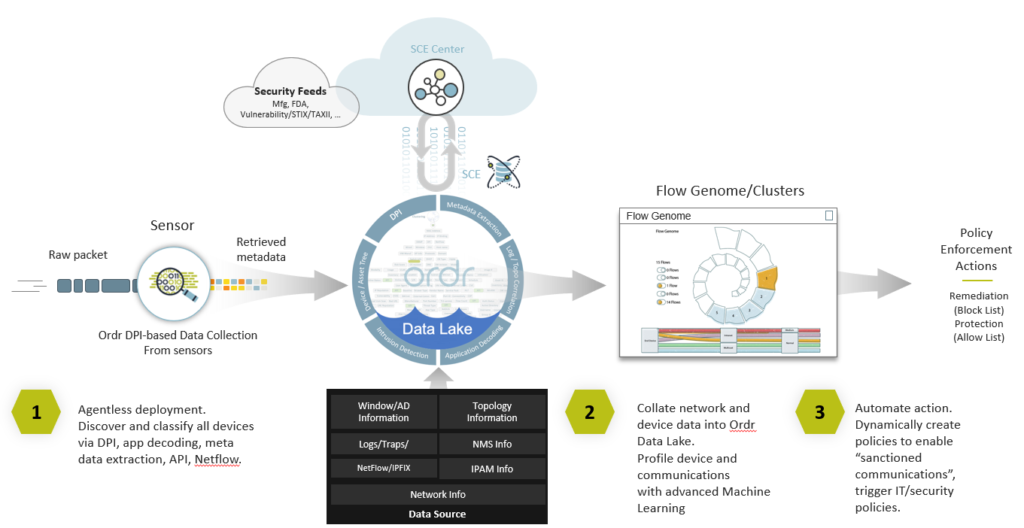
Part of my core responsibilities at Ordr is to expand the eco-system of integration partners. As we support more customer workflows, it is essential to allow more data into the Ordr Data-lLake for enrichment, but that data has to be of high trust and fidelity. That’s why we are embarking on adding a number of additional new integrations that provide us with unique contextual data to enrich our analysis and provide more insightful information and knowledge to our customers.
Integrations
In early 2021, we announced Ordr SCE 7.4.2, delivering more than 160 new features, integrations, and enhancements to provide unparalleled visibility and protection to organizations globally for security, IT, and HTM teams and their connected devices. In this release, we announced our integrations with Anomali, Exabeam, Fortinet, IBM QRadar, and Ping Identity. In this blog, I want to highlight the Anomali and Fortinet integrations, to give you an idea of the openness of our technology and the agnostic approach we are taking within the industry to ingest data or to use our device context to enrich or enforce policies in existing solutions:
- Anomali – Let’s start with Anomali, we worked with Anomali to ingest their STIX/TAXII 2.0 feed. Anomali consolidates various Cyber Threat Information (CTI) feeds and normalizes the data. Then, via a STIX/TAXII pull, Ordr is able to pull in the normalized data and enrich it with device context. The key to this is that we have built this using the very latest STIX/TAXII 2.1 standards. STIX/TAXII allows the sharing of CTI data. The CTI feed of data provides indicators of compromise, generally referred to as IOCs that allow Ordr SCE to find the needle in the haystack. The IOCs provide the bread-crumb-trail such that a vendor like Ordr can identify activity on the network that matches the signature of an IoC. This type of data is very targeted and is a true case of less is more.
- Fortinet – In contrast to the Anomali integration, which is very much an inbound ingest integration, our recent Fortinet integrations is primarily an outbound enforcement integration. We use AI and advanced machine learning, along with the Ordr Data Lake device context to create a complete Ordr Flow Genome profile of every device and its behavior. This baseline forms the foundation of segmentation policies to allow devices access while limiting exposure. We are leveraging the open API’s from FortiManager and FortiGate to enable Ordr to dynamically create and push out these enforcement policies. This can be to FortiGate firewalls or FortiNAC as an enforcement point. l said above it is primarily an outbound-based integration, but we also have the ability to consume basic traffic flow information from FortiGate to enhance and embellish the threat information we already have.
In the coming year, we are planning to implement additional inbound/outbound/bi-directional integrations for the benefit of our customers. As part of that process, we are constantly reviewing the integration use-cases developed to see where we can leverage more context to enable better device context.

Interested in
Learning More?
Subscribe today to stay informed and get
regular updates from ORDR Cloud


